Abstract
Recently, text-to-3D approaches have achieved high-fidelity 3D content generation using text description.
However, the generated objects are stochastic and lack fine-grained control.
Sketches provide a cheap approach to introduce such fine-grained control.
Nevertheless, it is challenging to achieve flexible control from these sketches due to their abstraction and ambiguity.
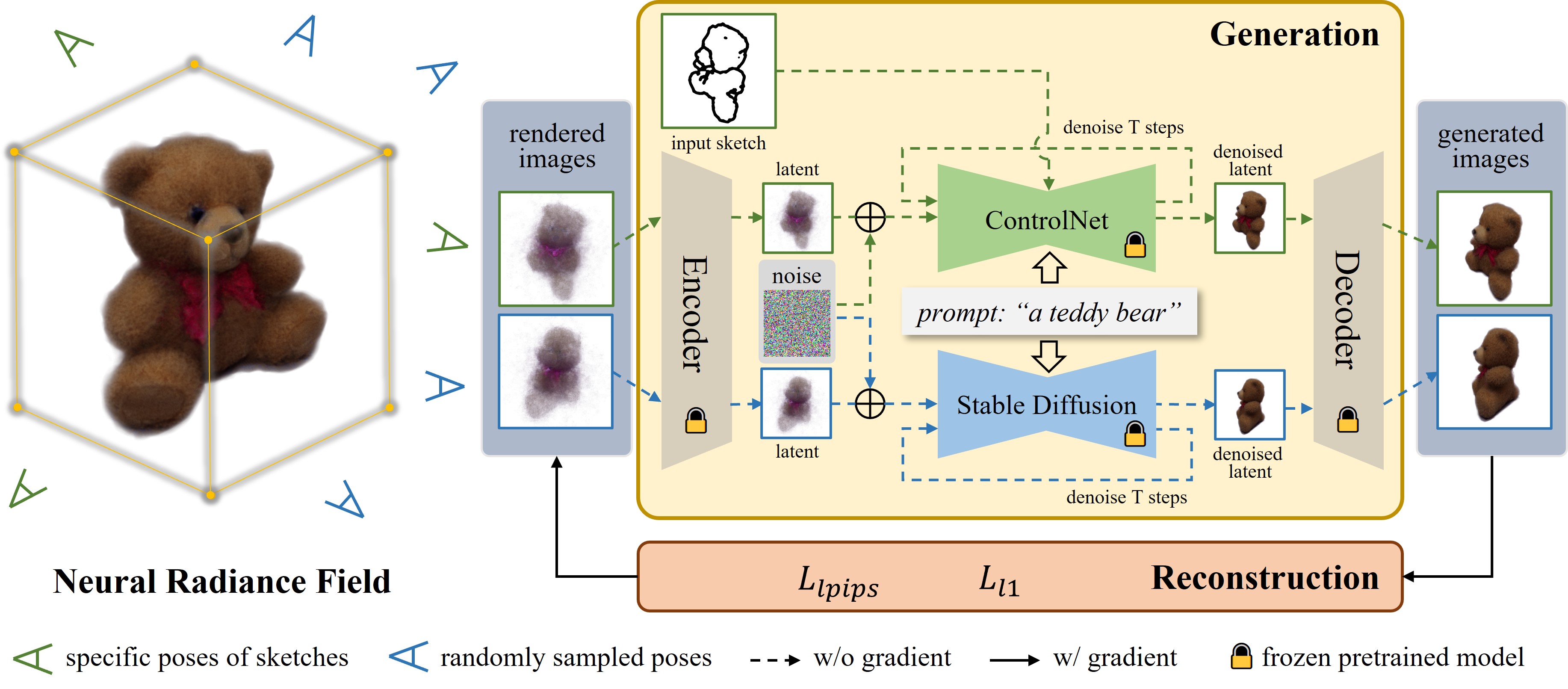
In this paper, we present a multi-view sketch-guided text-to-3D generation framework (namely, Sketch2NeRF) to add sketch control to 3D generation.
Specifically, our method leverages pretrained 2D diffusion models (e.g., Stable Diffusion and ControlNet) to supervise the optimization of a 3D scene represented by a neural radiance field (NeRF).
We propose a novel synchronized generation and reconstruction method to effectively optimize the NeRF.
In the experiments, we collected two kinds of multi-view sketch datasets to evaluate the proposed method.
We demonstrate that our method can synthesize 3D consistent contents with fine-grained sketch control while being high-fidelity to text prompts.
Extensive results show that our method achieves state-of-the-art performance in terms of sketch similarity and text alignment.